This session describes how to build a graphical calculation view in SAP HANA.
Prerequisite:
- You have SAP HANA Studio installed on your machine.
- You have added an SAP HANA system in HANA Studio.
- You have created the Analytic view mentioned in session 4.8
Scenario:In this calculation view we will consume the analytic view that provides Product ID, Region and Sales Amount. We will make a join with PRODUCT table to get Product Name.Further we will calculate Discount and Net Amount using following formula:If Product Name = “Purse” then Discount = 20%; Else Discount = 10%Net Amount = Sales Amount – DiscountSteps for creating Calculation view:
1. Right click on the package and choose New -> Calculation View.
2. Enter a name and a description. Select Subtype as “Standard”, Calculation View -> Type as Graphical and Data Category as “Cube”. Then click on “Finish”.
Note: Data Category can be of 2 types: Cube and Dimension.
Cube – “Cube” is selected when we want to define a calculation view that is visible in the reporting tools. This type of view must have at least one measure.
The default node is Aggregation or Star Join (based on the selection in the creation wizard).
Dimension – Dimension is selected when we want to define a simple calculation view which does not have any measure. This type of calculation view is not available in reporting tools. It can only be consumed via SQL queries.
The default node is Projection.
- You will see the graphical editor as shown in image below.
The Tool palette in the top-left corner contains the calculation view operators, which are
- Aggregation
- Projection
- Union
- Join
- You will see 2 blocks in the editor: Semantics and Aggregation.
Semantics provides the summary of output structure, editor view of output objects and general view properties.
Aggregation is the default top most node. It’s Aggregation because we had selected Data Category as “Cube”.
If we had selected Data Category as “Dimension”, then the default node would have been “Projection”.
- Click on the “Join” symbol and drag it in the scenario area to create Join block.
- Click on “+” sign of “Join” and add analytic view AV_SALES.
- Similarly add the PRODUCT table.
- In the Details area you will see the analytic view and table. Now we need to join these 2 components.
- Select the PRODUCT_ID from analytic view. Drag it and drop it on the PRODUCT_ID of PRODUCT table. Join type can be changed in the Properties tab. Let it be Inner Join as of now.
- Add all the columns of analytic view and table by right clicking and clicking on “Add To Output”. Alternatively you can also click on the grey color circle before the column name to add it to output.
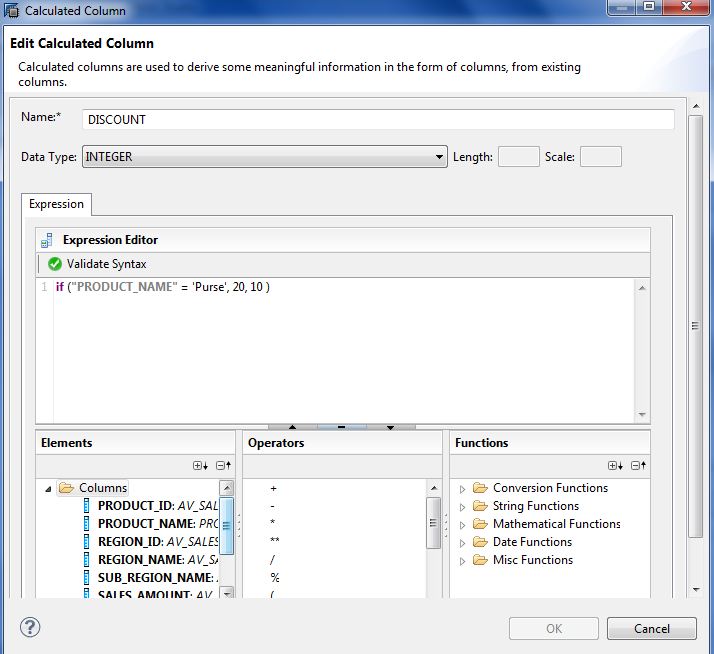
- Now we will calculate Discount and Net Amount using calculated column. Right click on the Calculated Columns and select New.
- Specify the name as DISCOUNT, select the Data Type as Integer. And provide the expression as
if (“PRODUCT_NAME” = ‘Purse’, 20, 10)
Note: The syntax of “if” operator is
If (condition, argument1, argument2)
Return argument1 if condition is true, else return argument2.
- Similarly create another calculated column NET_AMOUNT using the formula
“SALES_AMOUNT” – “DISCOUNT”
- Connect the Join block to Aggregation block with the arrow. Add PRODUCT_ID, PRODUCT_NAME, REGION_ID, REGION_NAME, SUB_REGION_NAME to output.
- Add SALES_AMOUNT and NET_AMOUNT as Aggregated Column.
- Select Semantics. Now we need to specify which columns are attributes and which columns are measures. Click on the “Auto Assign” button to do it automatically.
- Alternatively you can also specify the Attribute/measure by clicking on Type down-arrow.
- Activate the calculation view similar to attribute/analytic view.
- Right-click on your calculation view and choose “Data Preview”. After that, you can browse through the tabs named Raw Data, Distinct Values, and Analysis.
Analysis tab:
Raw Data tab: