What is ABAP Dictionary?
ABAP dictionary (Tcode SE11) is a central storage area fwhere we can create the objects and changing, deleting the objects relating to database. The main object type of ABAP dictionary are:
- Database table
- Data type
- Type group
- Search Help
- Domains
- View
- Lock objects
1. Database table: It helps in create and maintain the database tables.
There are 3 types of database tables:
1.1 Transparent tables (BKPF, VBAK, VBAP, KNA1, COEP)
Allows secondary indexes (SE11->Display Table->Indexes)
Can be buffered (SE11->Display Table->technical settings) Heavily updated tables should not be buffered.
1.2 Pool Tables (match codes, look up tables)
Should be accessed via primary key or
Should be buffered (SE11->Display Table->technical settings)
No secondary indexes
Select * is Ok because all columns retrieved anyway
Can not use Group-by SQL statement
1.3 Cluster Tables (BSEG,BSEC)
Should be accessed via primary key - very fast retrieval otherwise very slow
No secondary indexes
Statistical SQL functions (SUM, AVG, MIN, MAX, etc) not supported
Can not be buffered
Can not use Group-by SQL statement
- Specifications of the database tables:
- Delivery and Maintenance Tab:
- Delivery Class: Delivery class for controlling data transport of tables for installation, upgrade, client copy, and for transporting between customer systems. There are the following delivery classes:
- A: Application table (master and transaction data).
- C: Customer table, data is maintained by the customer only.
- L: Table for storing temporary data.
- G: Customer table, SAP may insert new data records, but may not overwrite or delete existing data records. The customer namespace must be defined in table TRESC. (Use Report RDDKOR54 here).
- E: System table with its own namespaces for customer entries. The customer namespace must be defined in table TRESC. (Use Report RDDKOR54 here.)
- S: System table, data changes have the same status as program changes.
- W: System table (e.g. table of the development environment) whose data is transported with its own transport objects (e.g. R3TR PROG, R3TR TABL, etc.).
- Behavior during Client Copy
- Only the data of client-dependent tables is copied.
- Class C, G, E, S: The data records of the table are copied to the target client.
- Class W, L: The data records of the table are not copied to the target client.
- Class A: Data records are only copied to the target client if explicitly requested (parameter option). It normally does not make sense to transport such data, but this is supported nevertheless to permit the entire client environment to be copied.
- Behavior during Installation, Upgrade and Language Import
- The behavior of client-dependent tables differs from that of cross-client tables.
- Client-Dependent Tables
- Class A and C: Data is only imported into client 000. Existing data records are overwritten.
- Class E, S and W: Data is imported into all clients. Existing data records are overwritten.
- Class G: Existing data records are overwritten in client 000. In all other clients, new data records are inserted, but existing data records are not overwritten.
- Class L: No data is imported.
- Cross-Client Tables
- Classes A, L and C: No data is imported.
- Classes E, S, and W: Data is imported. Existing data records with the same key are overwritten.
- Class G: Non-existent data records are inserted, but no existing data records are overwritten.
- Behavior during Transport between Customer Systems
- Data records of tables having delivery class L are not imported into the target system. Data records of tables having delivery classes A, C, E, G, S and W are imported into the target system (for client-dependent tables this is done for the target clients specified in the transport).
- Use of the Delivery Class in the Extended Table Maintenance
- The delivery class is also used in the Extended Table Maintenance (SM30). The maintenance interface generated for a table makes the following checks:
- It is not possible to transport the entered data using the transport connection of the generated maintenance interface for tables having delivery classes W and L.
- Data that is entered is checked to see if it violates the namespace defined in table TRESC. If the data violates the namespace, the input is rejected.
- Technical Settings: You use the technical settings of a table to define how the table is handled when it is created in the database. You can specify whether the table is buffered and whether changes to data records of the table are logged.

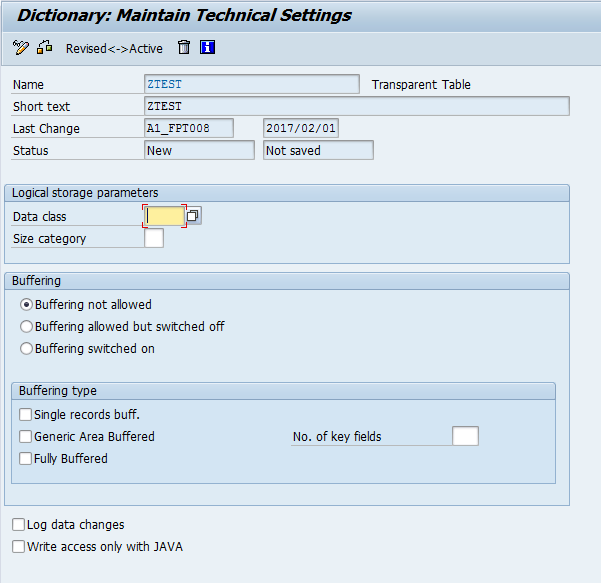
- Data Class: physical area of database where database table is stored.
- APPL0 (master data): Data which is seldomly changed. An example of master data is the data contained in an address file, such as the name, address and telephone number.
- APPL1 (transaction data): Data that is frequently changed. An example of transaction data is the goods in a warehouse, which change after each purchase order.
- APPL2 (organizational data): Customizing data that is defined when the system is installed and seldomly changed. An example is the table with country codes.
- Two further data classes, USR and USR1, are provided for the customer. These are for user developments. The tables assigned to these data classes are stored in a tablespace for user developments.
- Size category: the size category defines the size of the extents created for the table.
- Buffering permission: the buffering permission defines whether the table can be buffered.
- Buffering type: If the table can be buffered, you must define a buffering type (full, generic, single-record). The buffering type defines how many table records are loaded into the buffer when a table entry is accessed.
- Full buffering: The system loads all the records of the table into the buffer when one record of the table is accessed.
- Generic buffering: When a record of the table is accessed, all the records having this record in the generic key fields (part of the table key that is left-justified, identified by specifying a number of key fields) are loaded into the buffer.
- Single-record buffering: Only the records of a table that are really accessed are loaded into the buffer.
- Logging:
- This parameter defines whether the system logs changes to the table entries. If logging is switched on, the system records each change to a table record in a log table.
2. Data type: It helps to create Data element, Structure and Table type
- Data element:
- Describes the role played by a field in a technical context
- Fields of same semantic meaning can refer to the same data element
- Contains the field information (Field label, Search help, ..)
- Data element can be defined by Elementary Type or Reference Type (reference to a class, interface, a table, generic objects, ...)
- Structure:
- Structure is a data object that is made up of components of any data type stored one after the other in the memory.
- The following terms are important when we talk about structures:
- · Nested and non-nested structures
- · Flat and deep structures
- Nested structures are structures that in turn contain one or more other structures as components.
- Flat structures contain only elementary data types of fixed length (no internal tables, reference types, or strings). The term flat structure can apply regardless of whether the structure is nested or not. Nested structures are flat so long as none of the specified types is contained in any nesting level.
- Any structure that contains at least one internal table, reference type, or string as a component (regardless of nesting) is known accordingly as a deep structure.
- Only in the case of flat structures is the data content of the structure actually within the memory of the structure itself, while deep structures contain pointers to the data at the position of the deepest components. Since the field contents are not stored with the field descriptions in the case of deep structures, assignments, offset and length specifications and other operations are handled differently from flat structures.
Examples for Complex Data Types
- The following list contains examples of complex data types in ascending order of complexity:
- 1. Structures consisting of a series of elementary data types of fixed length (non-nested, flat structures)
- 2. An internal table whose line type is an elementary type (vector).
- 3. Internal tables whose line type is a non-nested structure ('real' table)
- 4. Structures with structures as components (nested structures, flat or deep)
- 5. Structures containing internal tables as components (deep structures)
- 6. Internal tables whose line type contains further internal tables.
- The graphic shows how elementary fields can be combined to form complex types.
- Table Type:
- You use a table type to provide the reference structure and functional attributes to the internal table in ABAP programs. You can reference a table type TTYP defined in the ABAP Dictionary with the command DATA <inttab> TYPE TTYP. You create an internal table <inttab> in the program with the attributes defined for TTYP in the ABAP Dictionary.
- A table type is defined by:
- its line type that defines the structure and data type attributes of a line of the internal table
- the primary key (see key definition and key category) and the secondary keys (optional) of the internal table. For more information, see Secondary Keys for Table Types.
- The row type (line type) is defined by directly entering the data type, length and number of decimal places or by referencing a data element, structured type (structure, table or view) or other table type. The row type can also be a reference type. You can see an example of row types in the figure below.


3. Type group: There are several type groups available in SAP. For example ‘ABAP’ and ’SLIS’ etc. To use them in program we use key word ‘TYPE-POOLS’. It allows us to define non-predefined types. Combination of all such non-predefined types is knows as type-pool or type-group. In simple terms, if we want to use some custom types in various programs then we need not define them separately, we can simply create a type group in ABAP dictionary and use that in our programs.
4. Search Help: It defines the search help (F4) for the fields of database table and helps in providing the values for a user search queries.
- Import parameters: Parameters with which context information from the screen may be copied to the help process.
- Export parameters: Parameters with which values from the hit list may be returned to the screen.
- LPos: Position of field in search help results report/table.
- SPos: Position of field in search help restriction screen.
- Default value: Set by the user parameter (eg. WRK (Plant), SPR (sy-langu)
5. Domains:
- Describes the technical characteristics of a table field
- Specifies a value range which describes allowed data values for the fields
- Fields referring to the same domain (via the data elements assigned to them) are changed when a change is made to the domain
- Ensures consistency
- Ex. Purchasing document number (EBELN)
- Value table can be assigned to a domain: A value table is used for domain level validations. Wherever you use this domain, if value table is assigned and relationship is created, the system will force you to enter only the values that are stored in value table.
6. View: It acts as virtual table and helps in retrieve the data from tables.
- These are advantages of view:
- Security
- Query Simplification
- Allows Different Perspective
- Schema Transparency / Location Transparency
- Schema Consistency
- Allows work-around for SQL limitations
- Possible to use the view buffer for inner join, which is usually bypassed by tables.
- These are different kinds of view:
- Database view: Database views are used to combine application data often distributed over several tables. The structure of such views is defined by specifying the tables and fields that are required. Fields which are not required can be hidden, thereby minimizing the interfaces. A view can be used in ABAP programs by Open SQL/Native SQL for data selection. If the database view only contains a single table, the maintenance status can be used to determine if data records can also be inserted with the view. If the database view contains more than one table, you can only read the data.Database views should be created if want to select logically connected data from different tables simultaneously. Selection with a database view is generally faster than access to individual tables.
- Projection view: Projection views are used to hide fields of a table. This can minimize interfaces; for example when you access the database, you only read and write the field contents actually needed. A projection view contains exactly one table. You cannot define selection conditions for projection views. There is no corresponding object in the database for a projection view. Access to a projection view is mapped by the SAP System onto the corresponding access to its base table. It is also possible to access pooled tables or cluster tables with a projection view.
- Help View: You have to create a help view if a view with outer join is needed as selection method of a search help. The selection method of a search help is either a table or a view. If you have to select data from several tables for the search help, you should generally use a database view as selection method. However, a database view always implements an inner join. If you need a view with outer join for the data selection, you have to use a help view as selection method.
- Maintenance view: Maintenance views offer easy ways to maintain complex application objects. Maintenance view cannot be used in ABAP Open SQL statements, only through Table maintenance (SM30) we can update the Data. We can display, modify, create the data for multiple tables from maintenance view.
7. Lock objects: Lock Object is a feature offered by ABAP Dictionary that is used to synchronize access to the same data by more than one program. Data records are accessed with the help of specific programs. Lock objects are used in SAP to avoid the inconsistency when data is inserted into or changed in the database.

No comments:
Post a Comment